반응형
반복문과 딕셔너리를 활용한 다중 파일 데이터 처리에 대해 말씀드리겠습니다.
다음 python 코드는 각 국가별 CSV 파일을 읽어 들이고, 데이터프레임의 크기를 출력하는 코드입니다.
korea = pd.read_csv('korea.csv')
japan = pd.read_csv('japan.csv')
china = pd.read_csv('china.csv')
print('korea:', korea.shape)
print('japan:', japan.shape)
print('china:', china.shape)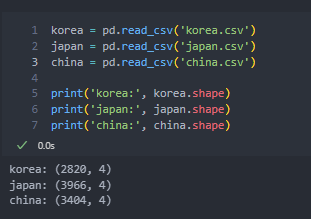
이 방법은 코드가 길어지고, 비슷한 작업이 반복되는 단점이 있습니다.
리스트가 적으면 상관없지만 리스트가 많아질 경우 코드가 길어질 수 있습니다.
다음과 같은 코드를 사용하여 동일한 결과를 도출합니다.
countries = ['korea', 'japan', 'china']
country_dataframes = {}
for country in countries:
country_dataframes[country] = pd.read_csv(f'{country}.csv')
for country, df in country_dataframes.items():
print(f'{country}:', df.shape)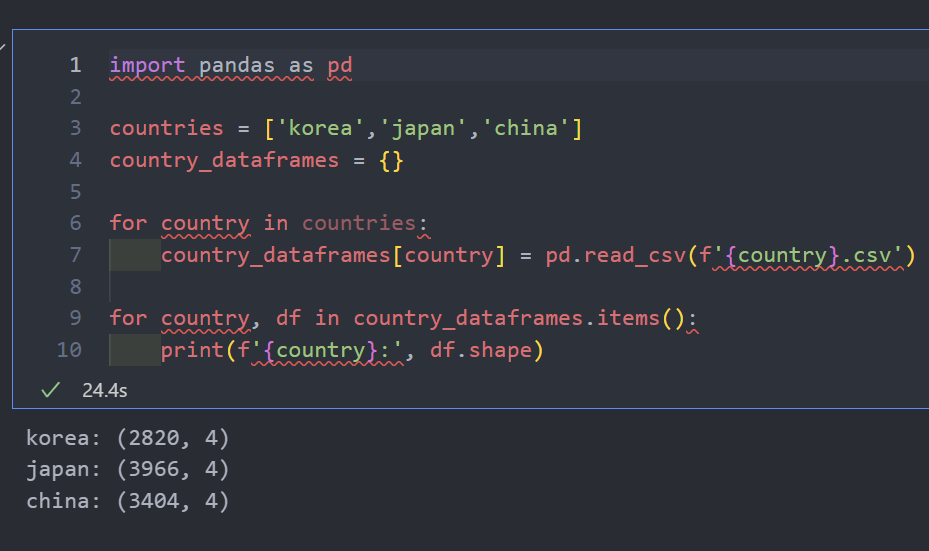
위 코드를 사용하면 각 데이터프레임은 딕셔너리에 저장됩니다.
또한, 딕셔너리를 순회하며, 각 국가별 데이터프레임의 크기를 출력하는 것과 같이 데이터프레임별로 작업을 수행할 수 있습니다.
코드가 간결해지고 비슷한 작업을 줄일 수 있으며 리스트에 파일 이름만 추가하면 되기 때문에 더 효율적인 작업이 가능합니다.
반응형
'Skills > Python' 카테고리의 다른 글
| pip로 라이브러리 설치 후 ModuleNotFoundError 오류 해결법 (0) | 2023.05.23 |
|---|---|
| Pandas를 사용해서 여러 csv 파일 합치기 (0) | 2023.03.23 |
| 파이썬으로 그룹별 합계와 총합계 구하기 (0) | 2023.03.22 |